
Data engineers are more important than your trophy data scientists. There… I said it! Well to be fair, we all have a role to play on the team but the reality is, if we have no data or data that hasn’t been prepared, we can’t really do any good analysis to extract insights from. The Data Engineers are the foundation of allowing good data science work to be done…”the best friends of data scientists you forgot to hire”. A sort of hybrid between a data analyst getting “dirty” with the data and a software engineer creating the infrastructure to allow the data to be used upon. This is a pretty cool quote that ties it well together:
“A scientist can discover a new star, but he cannot make one. He would have to ask an engineer to do it for him.”
–Gordon Lindsay Glegg
Broadly speaking, data engineers are focussed on the aspects of data that deal with production readiness in terms of
1. Formatting
2. Scaling
3. Security
4. Resilience
5. Performance and more
In the past, data scientists dealt with the extraction and preparation of the data as well as performing the analysis for actionable/predictive insight. However as the industry developed and Data Science became a more established “function” of an organization, these roles have become increasingly bifurcated particularly for much larger organizations where scale and performance become increasingly critical.
Essentially data engineers are responsible for the process flow of data from various data bases (internal and external) through to the analysts/analytics/intelligence specialists.
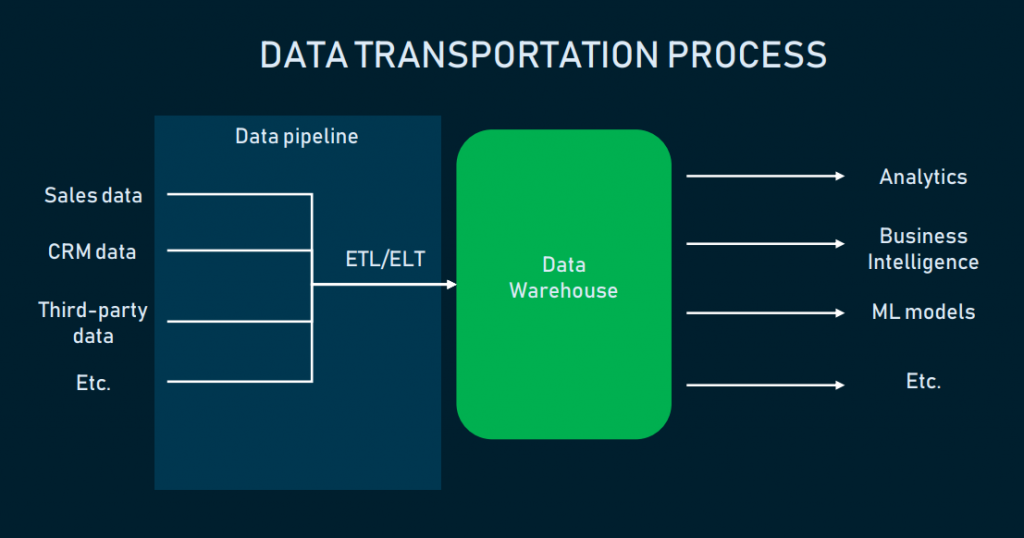
Data Warehouse
This is where all the core enterprise data is held and the storage repository. This can essentially be done on-site (banks have typically preferred this for security) or allowing it live “in the cloud” utiliszing companies like Amazon and their AWS Cloud services. There are then mining tools that are used to interact with the warehouse and “mine” the data out. To get this data out we will need to build pipeline to create a “flow” for the end users’s consumption.
Data Pipeline
The focus is on capturing the many flows of data and integrating them using various tools for consumption by the data users. Constructing these data pipelines is the core responsibility of the data engineer. This requires advanced programming skills in an automated data flow process. Typically the engineer achieves this using ETL (ExtractTransformLoad) tools.
1. Extracting the data from various sources
2. Transforming the data to align it to the business standard or format
3. Loading the reformatted data into the data warehouse
Once we delve into much larger data sets – “Big Data” we get into Data Lakes – a vast pool of data stored in its raw native often unstructured form. These are vast amounts of highly scaleable fault-tolerant data sets typical to what you can imagine will be stored at places like Youtube, Amazon, Facebook and the likes. In this instance, due to size the ETL process becomes an ELT process.
Why would you use them? When you’re not yet sure how you plan to use the data. Typical examples of Data Lakes include Hadoop for example, which is an open-source Java based large-scale data processing framework. Other examples include Hive, Pig.
Resources for learning Data Engineering
- I love podcasts, great way to learn on the go and if you like that then the Data Engineering Podcast wont disappoint.
- If online courses are more your thing, then Data Camp Data Engineering with Python is worth trying or Coursera’s.
- And if a traditional text book is more your pace then O’Riley is a good start! A solid data engineer should have practical skills and experience in these key areas: Algorithms & Data structures, SQL, Distributed Systems, Advanced Programming like Python/Java and Big Data Frameworks.








Add Comment